Distributed consensus with Raft

When working with distributed systems so many of the problems we're trying to solve boil down to managing state across multiple nodes. Whether it's replicating databases, mirroring message queues or achieving consensus in a blockchain network, the crux of the problem is keeping a distributed state machine in sync.
Replication is not even the hardest problem. When working with a distributed system we have to pick a trade-off: consistency or availability (see CAP theorem). To illustrate this better I think it's helpful to start with what could go wrong:
- Fail-stop failure
- Byzantine failure
Fail Stop
Fail-stop failures happen when a node in a cluster stops responding. This could be caused by a crash, a network split or simply network delays (it's impossible to differentiate a network delay from a network failure). These types of failures can generally cause two types of problems: systems not available to respond to requests or corrupted data.
Systems that try to be highly available (AP) would generally accept requests on both sides of a network split, and when that split is healed, you run into a problem of reconciling different views of the latest data for each split. Depending on how that reconciliation is done, you can end up with corrupted or lost data.
Systems that try to be highly consistent (CP) will only accept requests to an elected leader. This means that clients can potentially get an error back if they send a request on the wrong side of a network split. Raft is purely a CP system. If you have 5 nodes and lose 2, the system will be available and consistent. Lose 3 nodes, and you are not highly available anymore because the remaining two nodes are in a stalemate trying to pick a leader.
Byzantine failure
This second class of failure is a lot more interesting. If previously we were concerned with data corruption or availability, in this case we ask ourselves: what if we have a malicious client that purposely sends us bad data that we replicate across the cluster?
If we do entertain the idea of trust-less distributed consensus, things start to extend from pure technical solutions into things like game theory: if we cannot stop someone we do not trust from acting maliciously, can we align our interests to ensure they would never do that in the first place?
We could impose fines on those node operators that cheat the system. An escrow service could lock deposit funds for everyone involved and penalize a bad actor. Proof of stake is one example of a consensus mechanism that locks a participant's funds and penalizes them if they act maliciously. Proof of work mechanisms make it as difficult to break the network as it is to profit by using it correctly.
One can look at blockchains beyong the hype, from a distributed systems perspective and see that they're really just Byzantine Fault-Tolerant Replicating State Machines. If in a classic distributed state machine we have a log of state changes from which we can reconstruct the state, in a blockchain our log is using cryptography to ensure past state changes cannot be modified.
Raft
Let's return to the subject of my write-up: Raft. In keeping true to the mission statement of this algorithm, I will attempt to explain it in layman terms in this next section. It is truly remarkable that you can digest a distributed consensus algorithm so easily. You may be wondering: why would I care about Raft, who uses that anyway?
Raft use cases generally fall into two categories: data replication or distributed coordination / metadata replication. Here are some examples:
- etcd, Consul or ZooKeeper are examples of metadata replication. They don't replicated data itself but store things like configuration settings or service discovery. etcd and Consul use Raft while Zookeeper uses Zab.
- MongoDB uses Raft for leader election but not data replication - what I called distributed coordination
- InfluxDB uses Raft to replicated meta-data about its nodes
- RabbitMQ uses Raft to replicate data in Quorum Queues
There's even a blockchain project that allows you to use Raft for establishing consensus. Although not using Raft, Tendermint is another very interesting project worth checking if if you're into distributed consensus and blockchains.
Raft Nodes

I will preface this by sharing an absolutely amazing visualization of Raft that I used while learning this. If you are more of a visual learner, I highly recommend checking this Raft explanation out!
Nodes in a Raft cluster all start as Followers. The other possible states they can be in are Candidates or Leaders. Each node is initialized with a random election timeout (150-300ms) and the first node to reach that timeout will promote itself to Candidate.
Note that in order to prevent a stale mate, the election timeout has to be higher than the amount of time it takes for nodes to send messages to each other. The life cycle of a Raft cluster alternates between election and normal operation.
Elections happen when a Leader becomes unresponsive and does not send heart beats to all the nodes in the cluster. In order to keep all nodes in sync about the current cycle, we store and replicate a term on each node. A term is a monotonically increasing number stored on each node. Initially all nodes start at term 0. After the first election is successful, all nodes will bump the term to 1 and so on.
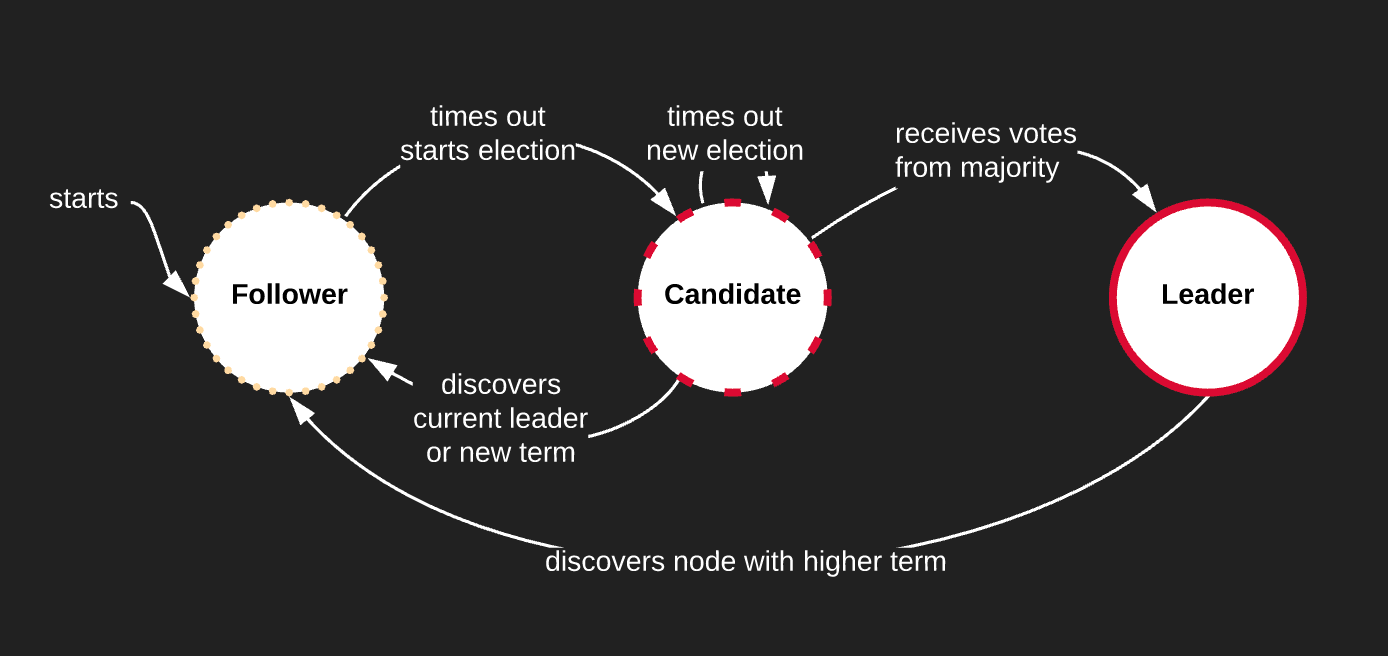
The term also helps when a network split occurs: if we have two leader elections in each split but only one completes successfully and therefore bumps the term, when we recover the lower term, the Leader steps down.
Leader Election
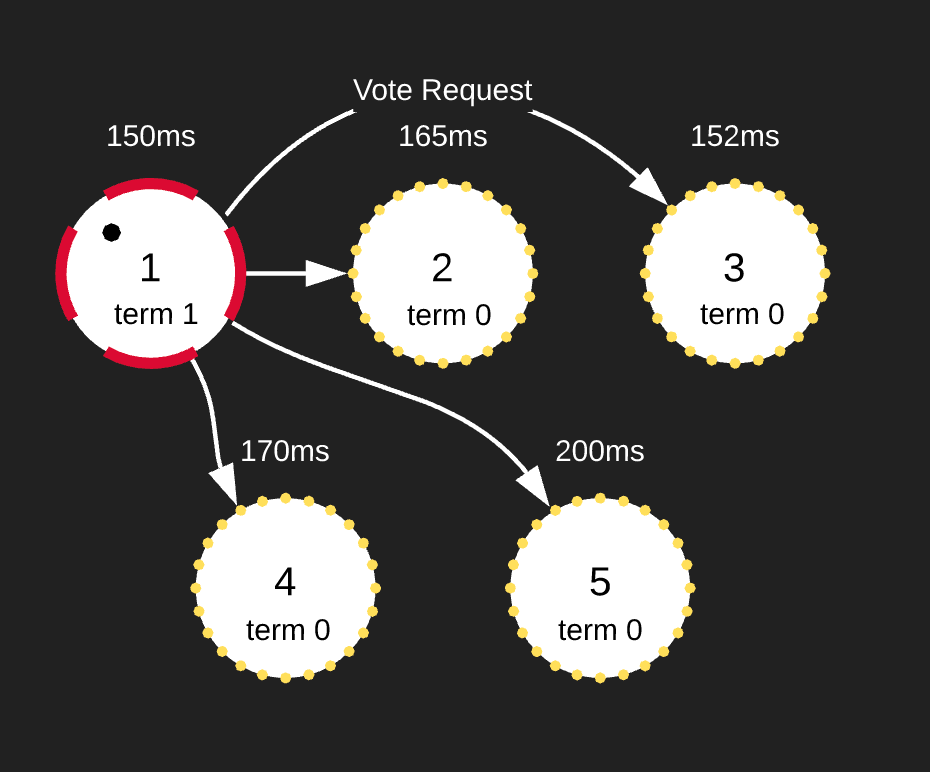
After the Candidate node times out, it votes for itself, bumps up the term and sends Vote Requests to all other nodes. If they have not voted yet in this term, they send their votes back. As soon as the Candidate node reaches a majority vote, it promotes itself to the Leader and starts sending Append Entries messages as heartbeats (the interval is configured by the heartbeat timeout). These Append Entries serve a dual purpose: after the Leader is elected, they are used to replicate data from the Leader to the rest of the nodes as well as heart beats.
We could run into a scenario where two nodes reach election timeout at the same time and both send Vote Requests. In this scenario, none of the Candidates will receive majority, the election timeout is once again randomized and the process repeats until only one Candidate self-promotes.
Log Replication
Raft is an example of an asymmetric consensus, meaning all requests are handled by the Leader. Some implementations would accept requests on any node and redirect that to the Leader. This does have the potential to bottleneck the Leader. Generally, you won't find clusters of Raft with more than 5 nodes in the wild. For example, YugabyteDB uses one Raft cluster for coordinating shard metadata, but for the actual data replication they employ a Raft shard per cluster.
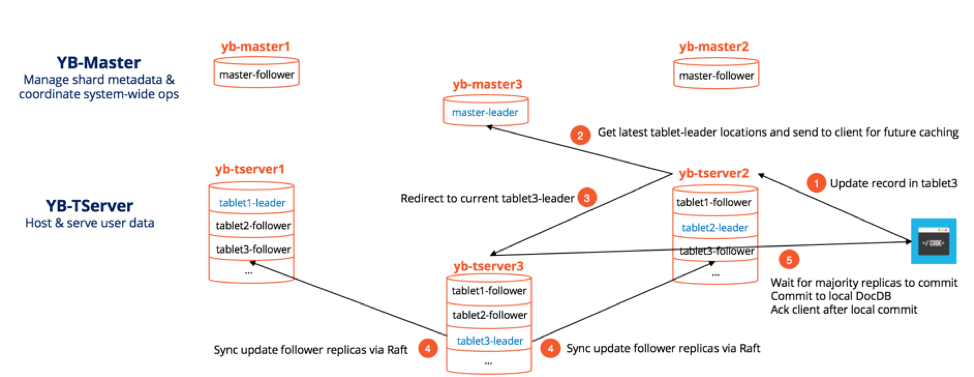
A client sends a change to the Leader and the Leader appends that change to its log (uncommited). The Leader then sends this change using an Append Entry message on the next heartbeat. Once the majority of the nodes respond that they also commited the change to their local logs, the Leader commits that change and responds to the client. It then sends another Append Entry message to let the nodes know that they should also commit that change.
Consistency during Network Partitions
Let's assume we have a 5 node cluster and a network partition separates that cluster into two groups of 3 and 2 nodes.
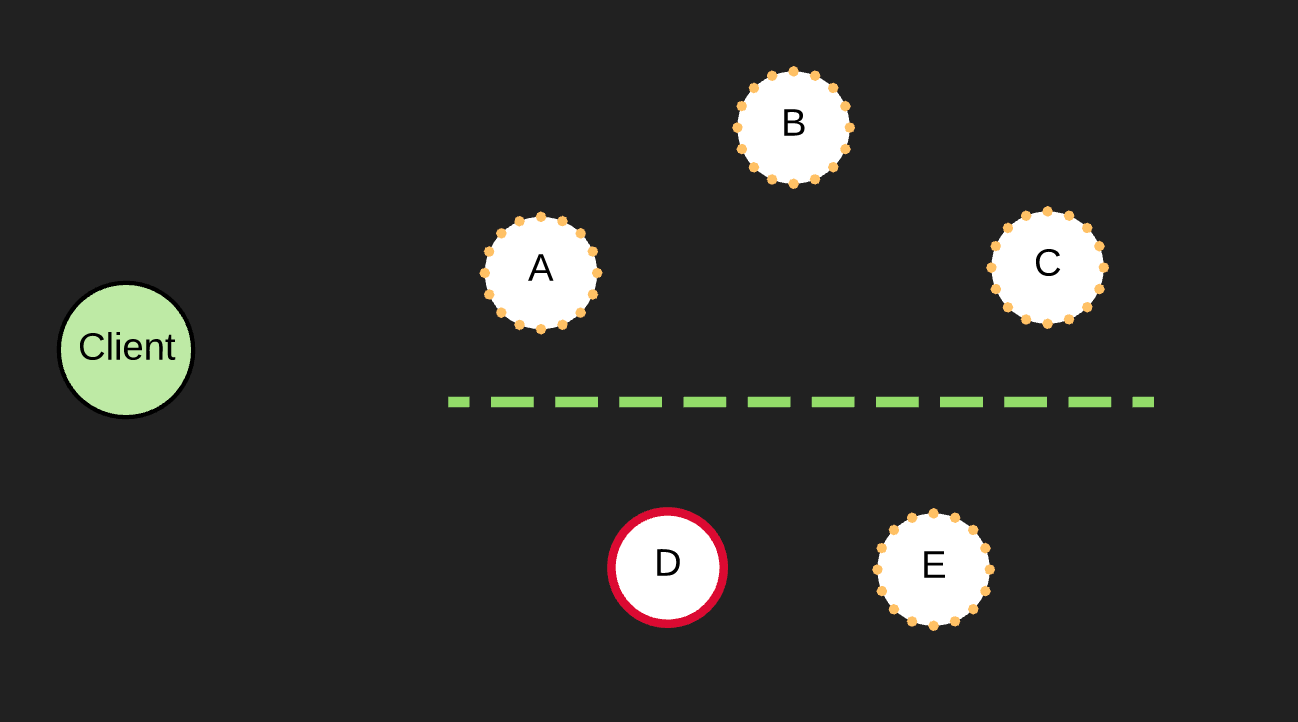
The top partition does not have a Leader, therefore after the heartbeat timeout is reached, one of the nodes will become a Candidate. A Leader can be elected in this case and the election term will be bumped.
With two Leaders across partitions we can potentially have two clients making requests to each Leader. The top partition will successfully commit the change because it will achieve majority, but the bottom will not, as the entry will stay uncommited in both the Leader and the Follower.
Once the partition is healed, the bottom Leader will receive a heart beat and see a higher election term. It will step down and roll back their uncommited changes to match the new Leader. This gets the whole cluster back to a consistent replicated state.
You can see why an AP system could end up with bad data. If a client sends a request to the bottom split and we acknowledge that request as successful, when the split heals we discard those changes leading to data loss.
Fun with Elixir
What initially prompted my research into Raft was Chris Keathley's Elixir implementation. Although not complete, it is a great reference implementation in a very suitable language. OTP makes it very easy to send RPC requests between nodes, having Dynamic Supervisors restart the nodes is super handy and GenServers make it easy to work with both timeouts and asyncrounous message passing. On top of that, the library comes with a GenStateMachine you can use to manage the state. You can use the macro provided or roll your own module. Data is stored on disk using RocksDB.
The following is the lib/raft/server.ex. It initializes each node, reads the logs from disk, if such exist, and recurses on reset_timeout.
def init({:follower, name, config}) do
Logger.info(fmt(%{me: name}, :follower, "Starting Raft state machine"))
%{term: current_term} = Log.get_metadata(name)
configuration = Log.get_configuration(name)
state = %{ @initial_state |
me: name,
state_machine: config.state_machine,
state_machine_state: config.state_machine.init(name),
config: config,
current_term: current_term,
configuration: configuration,
}
Logger.info(fmt(state, :follower, "State has been restored"), [server: name])
{:ok, :follower, reset_timeout(state)}
end
The server module is the heart of the implementation and is neatly organized into the Follower and Leader callbacks.
Peers are started as Dynamically Supervised children. This ensures that if one of them goes down, the children will get restarted. Also, if the Raft.Server.Supervisor crashes, it will restart the children once it comes back up.
def start_peer(name, config) do
DynamicSupervisor.start_child(__MODULE__, {PeerSupervisor, {name, config}})
end
RPC calls between nodes are also supervised:
def send_msg(rpc) do
Task.Supervisor.start_child(Raft.RPC.Supervisor, fn -> do_send(rpc) end)
end
defp do_send(%{from: from, to: to}=rpc) do
to
|> Server.to_server(to)
|> GenStateMachine.call(rpc)
|> case do
%AppendEntriesResp{}=resp ->
GenStateMachine.cast(from, resp)
%RequestVoteResp{}=resp ->
GenStateMachine.cast(from, resp)
error -> error
end
end
What's the use case for an Elixir Raft implementation?
Since I am just speculating here, it is advisable to take all of this with a grain of salt.
Here is a useful quote from Erlang and OTP in Action to kick off this discussion:
A cluster of Erlang nodes can consist of two or more nodes. As a practical limit, you may have a couple of dozen, but probably not hundreds of nodes. This is because the cluster is a fully connected network, and the communication overhead for keeping machines in touch with each other increases quadratically with the number of nodes.
This is good to keep in mind. One use case for Raft I could think of is replacing the global process registry with a Raft cluster, to distribute meta information about name -> node@pid mappings. This allows to run as many nodes as you want, without running them in a cluster and relying on an external system for coordination. I have heard of some doing this in the wild with ZooKeeper. You will also run into Raft if you decide to go the Kubernetes way: the etcd distributed key value store establishes consensus using Raft and is used to store all data in Kubernetes (its configuration data, its state, and its metadata).
Member discussion